
- Creating an Informative AI Wrapper Website
- Creating a Comprehensive Website for AI Wrapper
- Why the “Ai Wrapper” is the New Backbone of the Web

- 🤖 What Is an AI Wrapper? A Complete Beginner-to-Advanced Guide

- AI Wrapper Startups: The Fastest Growing Trend in the AI Industry
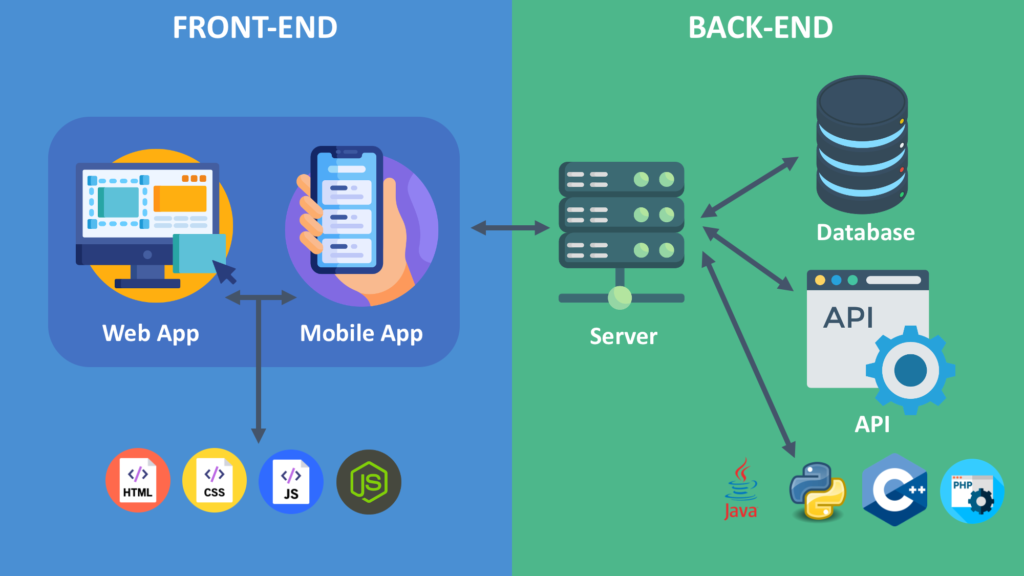
- How to Build AI Wrapper Apps (Step-by-Step for Beginners) Complete Guide



How OmniChat automated support with AI Wrapper
A flexible API layer that turns any LLM into a production‑ready assistant — 3x faster integration, 70% fewer tickets.
The challenge
OmniChat, a fast‑growing messaging platform for e‑commerce, faced ticket overflow. 40% of queries were repetitive (order status, refunds, technical setup). Their human support team couldn’t scale, and response times stretched to 6+ hours. They needed a smart layer to wrap AI models without building complex infrastructure from scratch.
- 8,000+ monthly support requests
- Only 20% handled by existing rules‑based bot
- High agent burnout, CSAT below 82%
The solution: AI Wrapper
With AI Wrapper’s unified API, OmniChat connected GPT-4 and their internal knowledge base in under two weeks. The wrapper handled prompt templating, context injection, fallback logic, and guardrails — so developers could focus on the frontend.
- Pre‑built connectors to 5+ LLMs (Azure, OpenAI, Claude)
- Semantic caching reduced costs by 37%
- Built‑in PII redaction & moderation
Implementation highlights
The AI Wrapper orchestration layer allowed OmniChat to create “skill‑specific” agents: one for billing, one for order tracking, and one for technical FAQ. Each used the same API but different prompt templates and data sources. The wrapper’s built‑in observability gave the team immediate insight into token usage and accuracy.
Measurable results
Within 30 days, deflection rate hit 70%, and agent workload shifted to complex cases. CSAT improved to 94%. The AI Wrapper’s unified analytics helped the team continuously fine‑tune prompts, improving resolution rate by another 11% in Q2.
“AI Wrapper wasn’t just an API — it was the missing glue between our support team and cutting-edge LLMs. We went from prototype to production in 10 days, and our agents now focus on work that actually makes a difference.”